
Basics of model predictive control#
Model predictive control (MPC) is a control scheme where a model is used for predicting the future behavior of the system over finite time window, the horizon. Based on these predictions and the current measured/estimated state of the system, the optimal control inputs with respect to a defined control objective and subject to system constraints is computed. After a certain time interval, the measurement, estimation and computation process is repeated with a shifted horizon. This is the reason why this method is also called receding horizon control (RHC).
Major advantages of MPC in comparison to traditional reactive control approaches, e.g. PID, etc. are
Proactive control action: The controller is anticipating future disturbances, set-points etc.
Non-linear control: MPC can explicitly consider non-linear systems without linearization
Arbitrary control objective: Traditional set-point tracking and regulation or economic MPC
constrained formulation: Explicitly consider physical, safety or operational system constraints
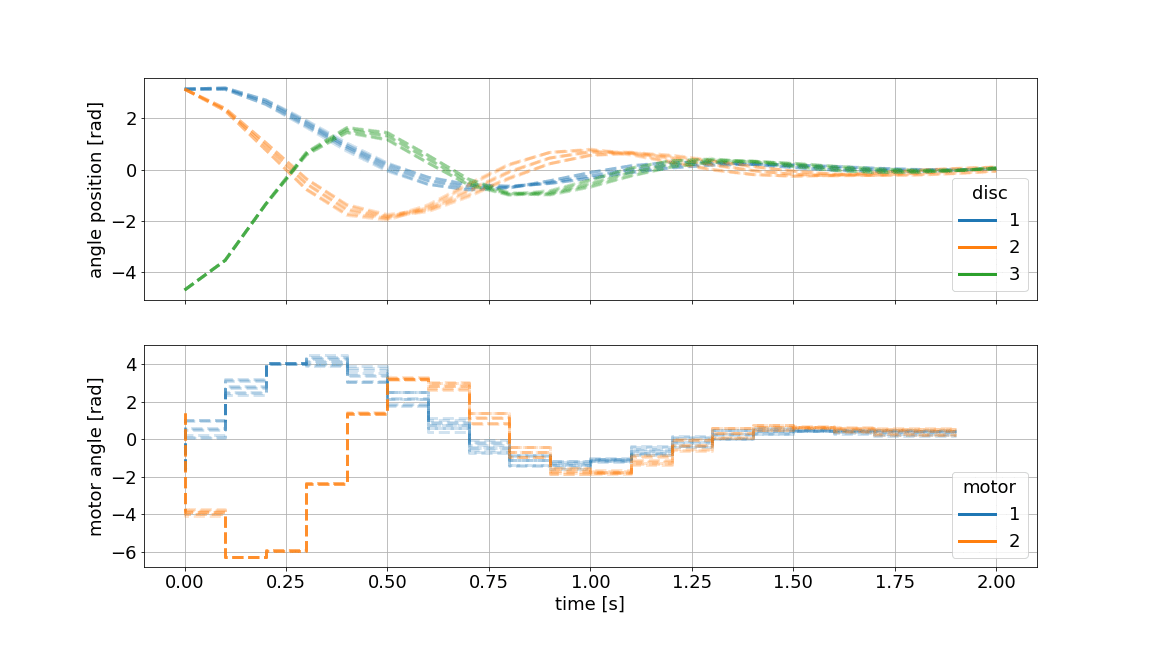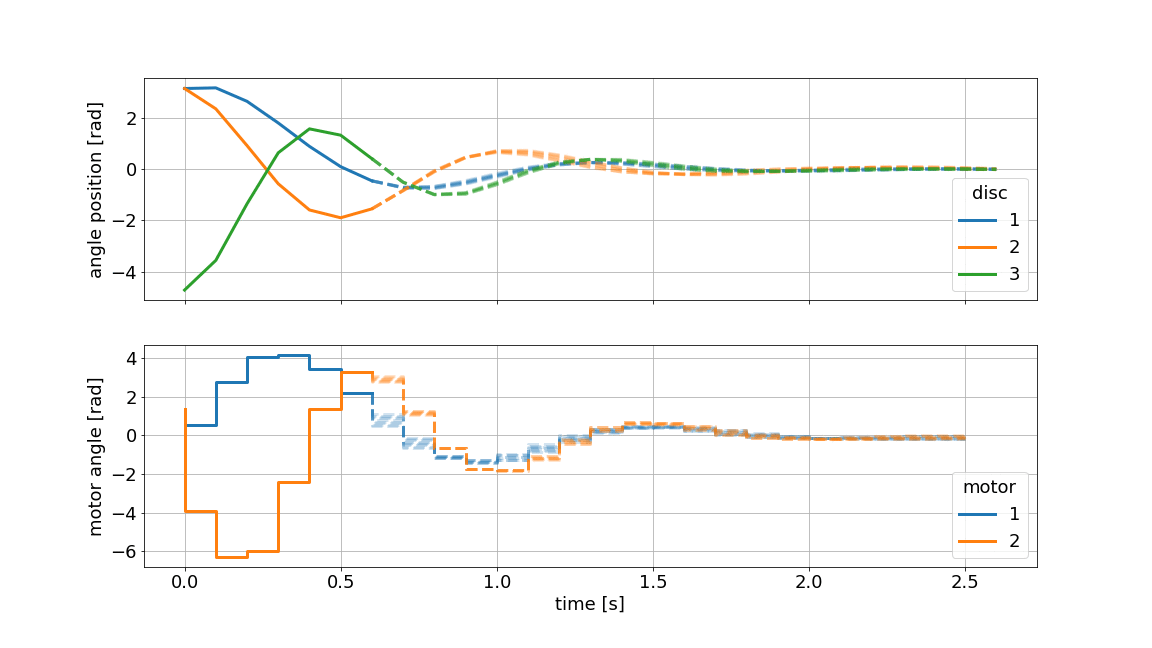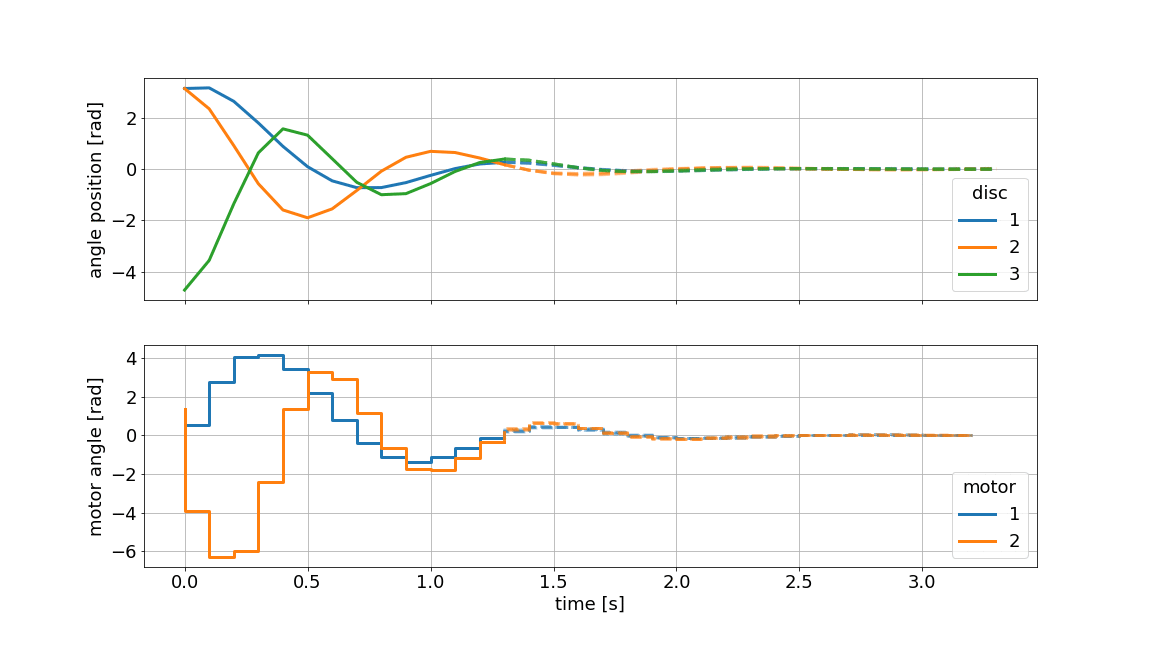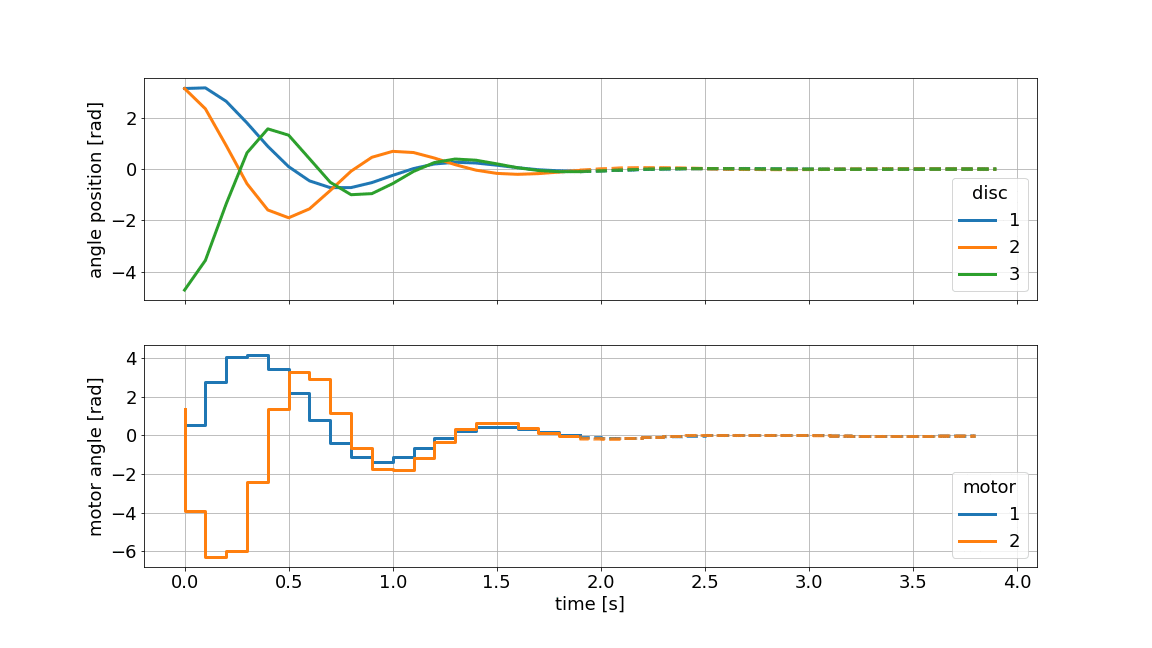
The MPC principle is visualized in the graphic above. The dotted line indicates the current prediction and the solid line represents the realized values. The graphic is generated using the innate plotting capabilities of do-mpc.
In the following, we will present the type of models, we can consider. Afterwards, the (basic) optimal control problem (OCP) is presented. Finally, multi-stage NMPC, the approach for robust NMPC used in do-mpc is explained.
System model#
The system model plays a central role in MPC. do-mpc enables the optimal control of continuous and discrete-time nonlinear and uncertain systems. For the continuous case, the system model is defined by
and for the discrete-time case by
The states of the systems are given by \(x(t),x_k\), the control inputs by \(u(t),u_k\), algebraic states by \(z(t),z_k\), (uncertain) parameters by \(p(t),p_k\), time-varying (but known) parameters by \(p_{\text{tv}}(t),p_{\text{tv},k}\) and measurements by \(y(t),y_k\), respectively. The time is denoted as \(t\) for the continuous system and the time steps for the discrete system are indicated by \(k\).
Model predictive control problem#
For the case of continuous systems, trying to solve OCP directly is in the general case computationally intractable because it is an infinite-dimensional problem. do-mpc uses a full discretization method, namely orthogonal collocation, to discretize the OCP. This means, that both the OCP for the continuous and the discrete system result in a similar discrete OCP.
For the application of MPC, the current state of the system needs to be known. In general, the measurement \(y_k\) does not contain the whole state vector, which means a state estimate \(\hat{x}_k\) needs to be computed. The state estimate can be derived e.g. via moving horizon estimation.
The OCP is then given by:
where \(N\) is the prediction horizon and \(\hat{x}_0\) is the current state estimate, which is either measured (state-feedback) or estimated based on an incomplete measurement (\(y_k\)). Note that we introduce the bold letter notation, e.g. \(\mathbf{x}_{0:N+1}=[x_0, x_1, \dots, x_{N+1}]^T\) to represent sequences.
do-mpc allows to set upper and lower bounds for the states \(x_{\text{lb}}, x_{\text{ub}}\), inputs \(u_{\text{lb}}, u_{\text{ub}}\) and algebraic states \(z_{\text{lb}}, z_{\text{ub}}\). Terminal constraints can be enforced via \(g_{\text{terminal}}(\cdot)\) and general nonlinear constraints can be defined with \(g(\cdot)\), which can also be realized as soft constraints. The objective function consists of two parts, the mayer term \(m(\cdot)\) which gives the cost of the terminal state and the lagrange term \(l(\cdot)\) which is the cost of each stage \(k\).
This formulation is the basic formulation of the OCP, which is solved by do-mpc. In the next section, we will explain how do-mpc considers uncertainty to enable robust control.
Note
Please be aware, that due to the discretization in case of continuous systems, a feasible solution only means that the constraints are satisfied point-wise in time.
Robust multi-stage NMPC#
One of the main features of do-mpc is robust control, i.e. the control action satisfies the system constraints under the presence of uncertainty. In particular, we apply the multi-stage approach which is described in the following.
General description#
The basic idea for the multi-stage approach is to consider various scenarios, where a scenario is defined by one possible realization of all uncertain parameters at every control instant within the horizon. The family of all considered discrete scenarios can be represented as a tree structure, called the scenario tree:

where one scenario is one path from the root node on the left side to one leaf node on the right, e.g. the state evolution for the first scenario \(S_4\) would be \(x_0 \rightarrow x_1^2 \rightarrow x_2^4 \rightarrow \dots \rightarrow x_5^4\). At every instant, the MPC problem at the root node \(x_0\) is solved while explicitly taking into account the uncertain future evolution and the existence of future decisions, which can exploit the information gained throughout the evolution progress along the branches. Through this design, feedback information is considered in the open-loop optimization problem, which reduces the conservativeness of the multi-stage approach. Considering feedback information also means, that decisions \(u\) branching from the same node need to be identical, because they are based on the same information, e.g. \(u_1^4 = u_1^5 = u_1^6\).
The system equation for a discretized/discrete system in the multi-stage setting is given by:
where the function \(p(j)`\) refers to the parent state via \(x_k^{p(j)}\) and the considered realization of the uncertainty is given by \(r(j)\) via \(d_k^{r(j)}\). The set of all occurring exponent/index pairs \((j,k)\) are denoted as \(I\).
Robust horizon#
Because the uncertainty is modeled as a collection of discrete scenarios in the multi-stage approach, every node branches into \(\prod_{i=1}^{n_p} v_{i}\) new scenarios, where \(n_p\) is the number of parameters and \(v_{i}\) is the number of explicit values considered for the \(i\)-th parameter. This leads to an exponential growth of the scenarios with respect to the horizon. To maintain the computational tractability of the multi-stage approach, the robust horizon \(N_{\text{robust}}\) is introduced, which can be viewed as a tuning parameter. Branching is then only applied for the first \(N_{\text{robust}}\) steps while the values of the uncertain parameters are kept constant for the last \(N-N_{\text{robust}}\) steps. The number of considered scenarios is given by:
This results in \(N_{\text{s}} = 9\) scenarios for the presented scenario tree above instead of 243 scenarios, if branching would be applied until the prediction horizon.
The impact of the robust horizon is in general minor, since MPC is based on feedback. This means the decisions are recomputed in every step after new information (measurements/state estimate) has been obtained and the branches are updated with respect to the current state.
Note
It the uncertainties \(p\) are unknown but constant over time, \(N_{\text{robust}}=1\) is the suggested choice. In that case, branching of the scenario tree is only required for first time instant (since the uncertainties are constant) and the computational load is kept minimal.
Mathematical formulation#
The formulation of the MPC problem for the multi-stage approach is given by:
The objective consists of one term for each scenario, which can be weighted according to the probability of the scenarios \(\omega_j\), \(j=1,\dots,N_{\text{s}}\). The cost for each scenario \(J_i\) is given by:
For all scenarios, which are directly considered in the problem formulation, a feasible solution guarantees constraint satisfaction. This means if all uncertainties can only take discrete values and those are represented in the scenario tree, constraint satisfaction can be guaranteed.
For linear systems if \(p_{\text{min}} \leq p \leq p_{\text{max}}\), considering the extreme values of the uncertainties in the scenario tree guarantees constraint satisfaction, even if the uncertainties are continuous and time-varying. This design of the scenario tree for nonlinear systems does not guarantee constraint satisfaction for all \(p \in [p_{\text{min}}, p_{\text{max}}]\). However, also for nonlinear systems the worst-case scenarios are often at the boundaries of the uncertainty intervals \([p_{\text{min}}, p_{\text{max}}]\). In practice, considering only the extreme values for nonlinear systems provides good results.
Other commonly used robust MPC schemes, such as tube-based MPC, are not currently implemented in do-mpc but planned for the near future. Please check our development roadmap on Github for details and updates.